The following is an excerpt from an email/blog I wrote for internal consumption by my development team, but I think the concepts are universal and worth sharing. I've removed any specific references to company intellectual property and otherwise "sanitized" the details, so some of the details are lost in the process.
For those unfamiliar with the term, Cyclomatic Complexity is a formula for determining the varying logical paths that can be taken though a piece of code, thus determining a quantitative value for the code's complexity. A higher Cyclomatic Complexity score means that there are a lot of code paths and/or factors that affect the logic with the code. One way to think about it is this: to fully unit test a method, you should have one unit test for each logic path - thus a score of 10 would result in as many unit tests. Wikipedia entry: http://en.wikipedia.org/wiki/Cyclomatic_complexity
The higher the CC score, the more difficult a piece of code is to read and understand, to test, and therefore, riskier to modify and maintain over time. A general rule-of-thumb suggests keeping the CC score to under 15 greatly improves readability, maintainability and reduces defects in the code. Anything above that, and the code is likely violating the single responsibility principle and is trying to do too much.
So why do I bring this up?
Because over the last 9 months as I've been learning the company's codebase and delving into many areas of code where I have no prior knowledge, I've come across sections of code which have been difficult to pick up and understand, and/or which requires and extraordinary amount of knowledge about the inner workings of that code and the code around it (tight coupling). And, as a direct corollary, this code is has low (or no) unit test coverage to protect us against mistakes and misunderstandings.
From theory to concrete examples:
A little further down, I will discuss how I suggest we address this issue, but first I want to give some concrete examples of what I'm talking about.
I was recently tasked with making a fairly straightforward change to what data is displayed in one of our "legacy" controls; however, it took me almost a full day just to wrap my head around what the control was doing and all of the (inconsistent) ways other classes/controls interacted with it.
Method: private void SelectAll(SelectAllMode mode)
Cyclomatic Complexity: 23
So what makes this method particularly problematic? Nested conditionals. At one point, there's:
- an if block,
- with a nested if block
- with a nested if block
- with a nested foreach loop
- with a nested if block
- with a nested switch block
- with a nested if block.
- with a nested switch block
- with a nested if block
- with a nested foreach loop
- with a nested if block
- with a nested if block
There are 11 if statements and 3 switch statements in a 96-line method -- 66 lines, if you don't count non-code lines.
Method: public void Initialize()
Cyclomatic Complexity: 17
This method does not have the level of conditionals of SelectAll(), but it does change behavior based on the type of a public property. In this case, the control accepts four types of DataSets (we utilize typed DataSets, which extend the DataSet class -- so there's a ProductDataSet, PricingPlanDataSet, etc) and acts differently based on the type of the dataset.
Another factor that affects code complexity is high levels of coupling with other classes, and in this case the Initalize() method is coupled with 36 other classes. This means that there is an increased potential that changes in those other classes will affect the logic in this method.
So, what can we, as developers, do?
Step 1: Knowing you have a problem
Aside from just generally being aware of Code Smells when you see them, there are a couple of tools that will help specifically call out Cyclomatic Complexity:

There is a free "CyclomaticComplexity PowerToy" ReSharper plugin that will mark any methods with a CC score above 17 with a ReSharper warning and display the CC score as a tooltip. It can be downloaded here: http://resharperpowertoys.codeplex.com/ (make sure to grab the v5.1 installer pack if you haven't upgraded from v5 -- the source code is already converted to use ReSharper v6). This will give you more "real time" warnings that things are ugly.
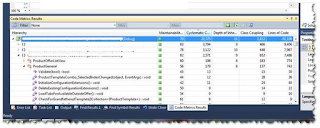
Additionally, Visual Studio 2010 Ultimate comes with code analytics features which will calculate several metrics for your code, including Cyclomatic Complexity, Depth of Inheritance, Class Coupling, Lines of Code, and something Microsoft calls a "Maintainability Index", where they try to apply an aggregation of the others to give you an overall score.
You can access this feature from the Analyze menu
This can be quite time consuming, though, depending on your hardware and the size of the Solution/Project you decide to analyze. At the end, VS2010 will spit out a report, which can be exported to Excel.
Step 2: Refactor to reduce complexity, improve understanding
I am a firm believer in a phase I picked up from Martin Fowler's writings (which he attributes to "Uncle Bob" Martin):
"always leave the code behind in a better state than you found it"
For me, this means small refactorings to address issues or improve understanding of the code. For example, if you're coming in to a piece of code and it takes you more than two minutes to figure out what the code is trying to do, you should look for ways to make the code more clear and embed the understanding you just gained into the code. Maybe that means pulling a set of lines out into their own method and naming that method in a way that makes it clear what those lines are doing. In other cases, it may be a larger refactoring effort.
The key here is make it better than you found it -- it doesn't have to be perfect. If everyone who touched the code makes it better each time, then those areas of the code that get touched a lot improve quickly -- which is good, because areas that change a lot are the places that have the most risk of getting broken.
So in my examples above, I would apply this rule in two ways:
- pull out those nested conditionals in SelectAll() into sub-methods (assuming there isn't a clear way to remove them altogether)
- utilize inheritance to reduce conditional blocks, such as those in Initialize(). By having the core/shared functionality in a base class, then having derived classes for each of the DataSet types, we could move the type-specific code into easier-to-maintain and smaller classes and greatly improve the readability and maintainability of the code.
Now, obviously I didn't do these things, otherwise they wouldn't still be here as examples. Why not? Well, because this class is tied to core functionality in our system and zero unit tests, so we would need considerable QA effort to regression test this functionality -- and had no QA resources available to do that. So from a risk standpoint, this was not the time to make changes. However, I do hope we can get scheduled time in the (near) future to do planned refactoring of this code.
Step 3: Don't make things worse
This one's easy: When writing new code, make sure it's clean, readable and testable.